Hey ya’ll i’m here to tell yall about my web app which is like a web app for hotels and hospitality industries or just about anyone who could use concierge or customer support service.
The idea was that if i’m a guest at a hotel and i want to know things like what the wifi password is, how i can get a taxi, what restaurants are in the area, what there’s to do in the area or things like that, i would have to talk to a concierge and ask them.
But that requires human interaction which is so 2024. I just want to text someone and get an instant response not send an email like what’s some good indian food in the area and wait an undetermined amount of time before i get a response, and i don’t want to make a phone call.
So what’s there to do? Well what about an AI concierge chat? And to access it you just have to scan a qr code that’s in the hotel which takes you to their chat web app and now you can chat with an AI concierge instead of making a call or email or having to shower and get dressed so you can talk to a stranger.
And that’s the platform I created. A platform that allows hotels (or anyone signing up) to upload their documents, have those documents turned into the knowledge base for the chat system, and then created a chat ui for interfacing with an AI api and their knowledge base.
This…is the technical tale…
Architectural choices
- Next.js - web app framework
- Supabase - database and user authentication
- PG Vector - vector embedding database storage
- Open AI API - AI api calls
Technical implementation
The foundation of this project was mainly from this mini course from Supabase. They created a course on how to upload documents, turn that into RAG embeddings, and create a chat app that interfaces with the RAG data.
I then turned the codebase into a saas platform where a user could create a chat, upload documents tied to that chat, create embeddings on those documents, and then get a url for their chat.
AI workflow
Regarding AI, there are two systems in this app.
- The RAG knowledge base for the hotel's chat data.
- The chat system which retrieves the data.
RAG Knowledge base
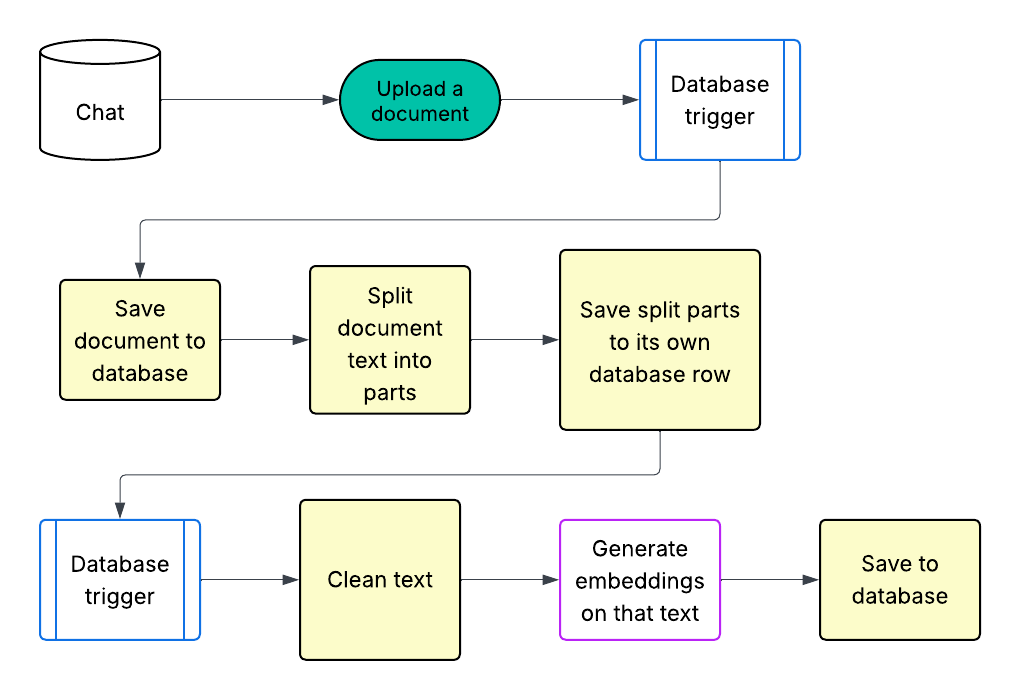
This system starts with a user’s chat object. The chat is created in the database and it allows users to upload documents linked to that chat.
Documents could be the hotel’s menu, their wifi information, hours of operation, contact information, nearby attractions, how to use the public transit or anything that a hotel’s concierge might know.
This knowledge from text is turned into embeddings and saved to the database and associated with the particular chat. When a user sends a message through the chat, the app turns the input into an embedding and retrieves the document section that matches closest and uses that to generate a response.
So if the user inputs “What’s the wifi information” this text gets turned into an embedding, gets sent to the backend, the backend retrieves the chat’s document embedding that matches closest to the user’s input, and then generates a response using this information and then sends that back to the frontend.
1. Upload file
The function which handles the frontend file uploading:
2. Supabase storage trigger gets called
After a document is uploaded to Supabase storage, a database trigger is activated. This trigger calls the process function:
The process function is a Supabase edge function:
2. Embed trigger gets called
After document sections are inserted into the database, another Supabase database trigger is called, embed.
This Supabase edge function turns the text into embeddings and saves it to the database.
We do this because we need to make the text searchable by meaning and not just keywords. By turning the text sections into embeddings, we can store their meaning as vectors in the database.
Then when the user asks the chat a question, we can search our database for text that matches the meaning of the input rather than just keywords.
After the embeddings are created and stored, the chat is ready to start its purpose.
Chat system
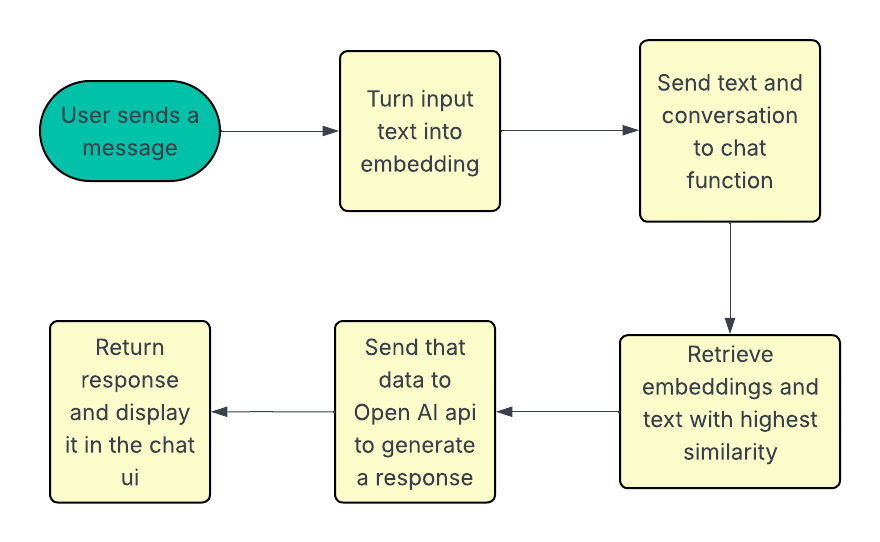
Now we're at the end user interface. Here is where the user is like going to enter their inputs.
1. Handle user input
2. Use pipeline function
This is a small helper that gives your React app a “backstage” assistant for AI. It starts a background worker in the browser, loads the model for you, and hands you one simple function to call for results.
Why it exists: Running AI on the main thread can slow or freeze your UI. This moves the heavy lifting off the main thread so scrolling, typing, and clicks stay smooth.
3. Chat edge function
The chat edge function is the Supabase edge function which takes the user's input, calls the database function, match_document_sections and returns the documents.
If relevant information about the user's query is found then it takes that text and adds it to the API call for context to generate a chat response.
It then returns the response to be added to the chat UI.
4. Match document sections
This is a SQL function.
It takes an embedding and returns the IDs and content of the documents most similar to the input embedding, ordered by the highest similarity.
Conclusion
In conclusion, I think this app is cool and had potential. A platform to create your own AI assisted knowledge chatbot is a powerful platform. I'm into building not marketing so I decided to move onto another project.